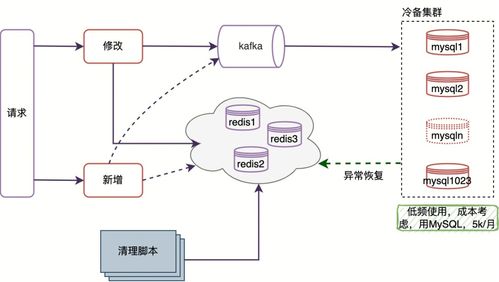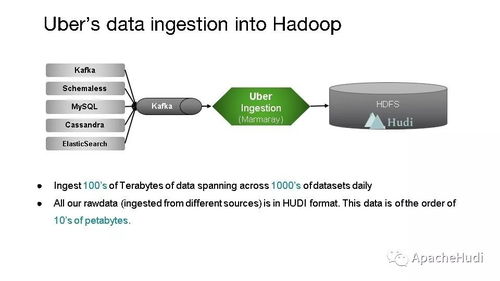
随着大数据时代的到来,企业对数据处理和分析的需求日益复杂,既需要支持传统的批处理任务,又要求能够进行近实时分析,以快速响应业务变化。Apache Hudi(Hadoop Upserts, Deletes & Incrementals)作为一种开源数据湖解决方案,通过统一的存储和服务层,成功解决了批处理和近实时分析之间的鸿沟,为现代数据架构提供了强大的支持。
Hudi 的核心优势在于其统一的数据存储和处理能力。它构建在 Hadoop 兼容的存储系统之上,如 HDFS 或云存储(例如 AWS S3),允许用户在同一数据湖中同时进行批处理(如每日 ETL 作业)和近实时分析(如流式数据摄取和查询)。通过引入 Upsert(更新插入)和增量处理机制,Hudi 高效地管理数据变更,避免了传统批处理中常见的全表重写问题,从而降低了存储成本并提高了处理效率。
在数据处理方面,Hudi 支持多种数据服务模式。例如,它提供了两种表类型:Copy-on-Write(写时复制)和 Merge-on-Read(读时合并)。Copy-on-Write 表适用于写操作较少的场景,通过直接在写入时更新数据文件来保证查询性能;而 Merge-on-Read 表则更适合高频率的写入场景,它将更新延迟到读取时合并,从而优化写入吞吐量,非常适合近实时数据流处理。这种灵活性使得 Hudi 能够适应不同业务需求,无论是历史数据分析还是实时监控。
对于存储支持服务,Hudi 集成了多种大数据生态系统组件,如 Apache Spark、Apache Flink 和 Presto/Trino,提供了无缝的数据摄取、转换和查询体验。用户可以利用 Hudi 的增量拉取功能,仅处理自上次处理以来的新数据,这大大减少了计算资源消耗,并加速了数据管道。Hudi 还支持事务性保证和数据版本管理,确保数据的一致性和可追溯性,这对于企业级应用至关重要。
实际应用中,许多公司已将 Hudi 部署在生产环境中,用于统一处理批量和流式数据。例如,在电商平台中,Hudi 可以同时处理历史订单的批分析(如月度销售报告)和实时订单流的近实时查询(如库存监控),实现了数据存储和服务的统一。这不仅简化了数据架构,还提升了整体数据处理的敏捷性和效率。
总而言之,Apache Hudi 通过其创新的存储设计和数据处理服务,成功将批处理和近实时分析融合在一起。它降低了数据湖的维护复杂度,同时提供了高性能和可扩展性,是企业构建现代化数据平台的理想选择。随着数据需求的不断演进,Hudi 将继续在统一数据处理领域发挥关键作用,助力企业实现更智能的数据驱动决策。