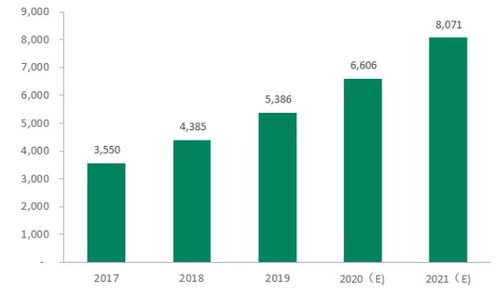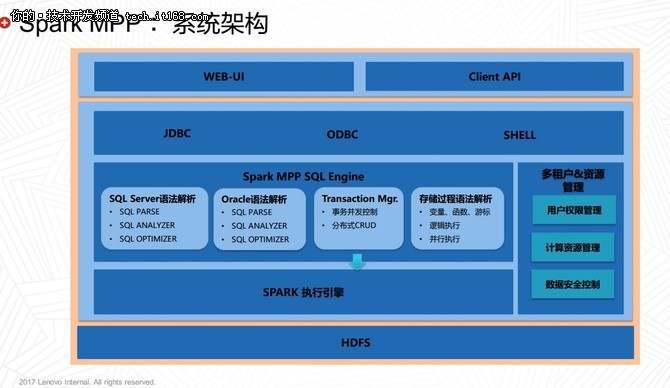
在当今大数据时代,企业对数据处理能力的需求日益增长,尤其是在高并发、实时分析场景下。Apache Spark作为主流的大数据处理引擎,以其内存计算和通用性广受青睐。在面对大规模并行处理(MPP)场景时,Spark的默认架构可能面临扩展性和性能瓶颈。本文探讨如何扩展Spark引擎以支持MPP计算场景,并聚焦数据处理和存储支持服务的优化策略。
理解MPP场景的核心需求是关键。MPP系统强调分布式计算节点间的并行协作,以处理海量数据查询和分析任务。Spark引擎通过其弹性分布式数据集(RDD)和DataFrame API提供了良好的基础,但原生Spark在跨节点数据交换和资源管理上可能不够高效。为此,扩展Spark需要从以下几个方面入手:
- 架构优化:引入MPP-aware的调度器,优化任务分配以减少数据倾斜。通过集成类似Apache Mesos或Kubernetes的资源管理器,实现动态资源分配,确保节点间负载均衡。利用Spark 3.0的Adaptive Query Execution特性,可以自动调整执行计划以适应MPP场景。
- 数据处理增强:在数据处理层,扩展Spark以支持更高效的并行算法。例如,通过自定义数据源API,集成列式存储格式如Apache Parquet或ORC,提升I/O性能。采用向量化执行引擎,减少函数调用开销,这在MPP查询中能显著提升吞吐量。开发者可以构建用户定义函数(UDF)和聚合器,以处理复杂逻辑,同时确保数据分区策略与MPP需求对齐。
- 存储支持服务:存储是MPP场景的基石。扩展Spark时,需要优化与分布式文件系统(如HDFS)或对象存储(如AWS S3)的集成。通过缓存机制(如Alluxio)减少数据读取延迟,并实现数据本地化策略。支持事务性存储(如Delta Lake)可以确保数据一致性,这对于实时MPP分析至关重要。在服务层面,提供监控和自动化工具,帮助运维团队管理存储资源,预防瓶颈。
- 性能调优与案例:在实际部署中,通过基准测试验证扩展效果。例如,某金融公司通过扩展Spark引擎,在MPP场景下处理TB级交易数据时,查询响应时间降低了50%。关键在于调整Spark配置参数(如executor内存、并行度),并结合硬件加速(如GPU)。IT168技术开发专区强调,这种扩展不仅提升了计算效率,还降低了总体拥有成本(TCO)。
扩展Spark引擎支持MPP计算场景是一个系统工程,涉及架构、数据处理和存储服务的全方位优化。随着数据量持续增长,这种扩展将帮助企业构建更敏捷的数据平台。结合AI驱动的自动化优化,Spark在MPP领域的应用前景广阔。开发者应持续关注社区动态,如Spark与云原生技术的融合,以保持技术领先。